Image Segmentation using Machine Learning
For this example, we will demonstrate image segmentation using machine learning with MoveIt Pro.
Setup
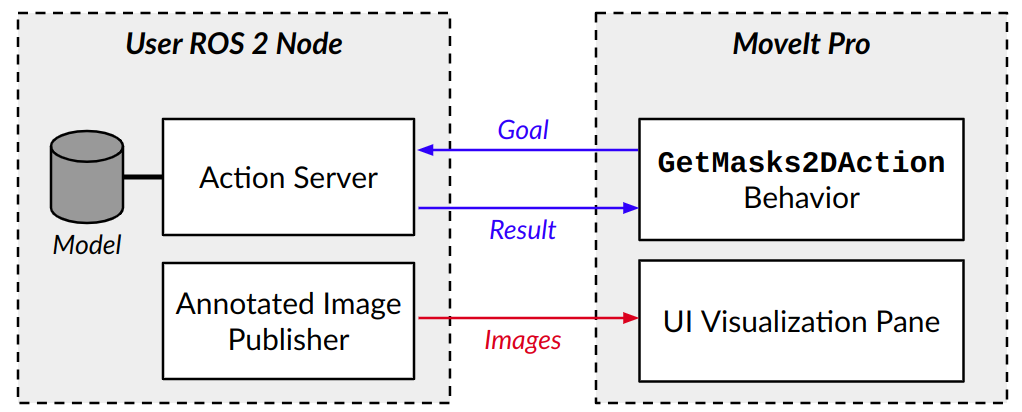
MoveIt Pro offers a GetMasks2DAction Behavior which can call out to an external ROS 2 action server that hosts an image segmentation model.
This action, named moveit_studio_vision_msgs/action/GetMasks2D is defined in the MoveIt Pro SDK.
You can create your own action server, typically in Python, to host your own segmentation model. In this example, we will use a Mask R-CNN segmentation model from the Detectron2 library, which in turn is based on PyTorch. Additionally, you can set up your server to publish annotated images to a ROS topic for visualization in the web app.
Note
Contact us if you would like access to the Mask R-CNN reference implementation.
In MoveIt Pro, launch the example UR5e Gazebo configuration by running:
moveit_pro run -c picknik_ur_gazebo_config
Performing 2D Image Segmentation
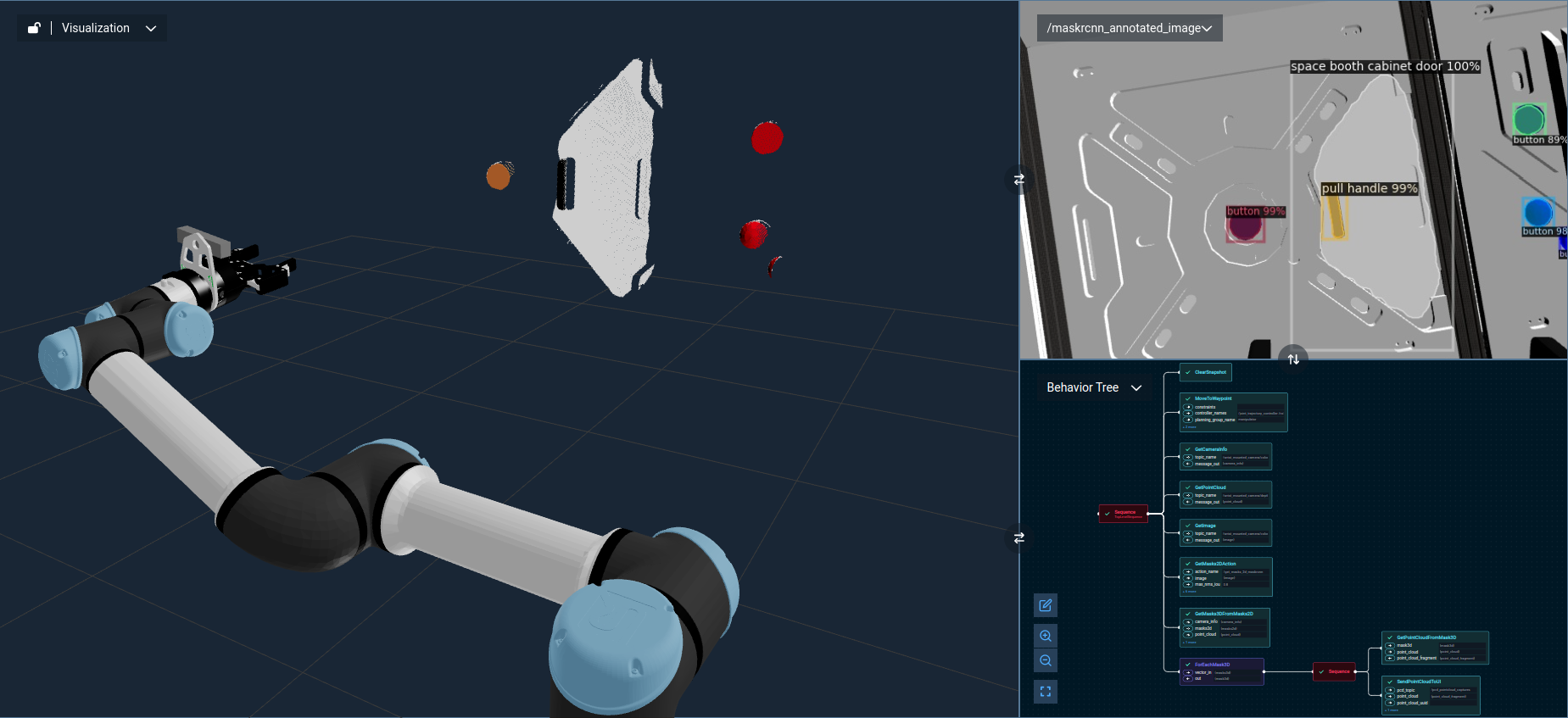
Once you have your segmentation action server running, you can create a simple Objective in MoveIt Pro that moves to a predefined location and performs detection.
MoveToWaypoint(or equivalent) to move to the predefined location.GetImageto get the latest RGB image message from a camera stream.GetMasks2DActionto request image segmentation.
To run this example, execute the Object Segmentation 2D Objective.
If you have configured your views to display the annotated image topic, you should be able to see the segmentation results in the UI.

Note that the GetMasks2DAction Behavior has additional options to filter detections by confidence score, target classes, and more.
Feel free to change the viewpoint and detection options to see how the results are affected.
Extracting 3D Masks and Fitting Geometric Shapes
The GetMasks2DAction Behavior outputs a list of masks, of ROS message type moveit_studio_vision_msgs/msg/Mask2D.
Many other Behaviors in MoveIt Pro can consume masks in this format for further processing.
For example, we can extend our Objective to convert the 2D segmentation masks to 3D point cloud segments by using the following Behaviors.
GetPointCloudandGetCameraInfoto get the necessary information for 2D to 3D segmentation correspondence.GetMasks3DFromMasks2D, which accepts the 2D masks, point cloud, and camera info to produce a set of 3D masks.ForEachMask3Dto loop through each of the detected masks.GetPointCloudFromMask3Dto get a point cloud fragment corresponding to a 3D mask.SendPointCloudToUIto visualize each point cloud segment above in the UI.
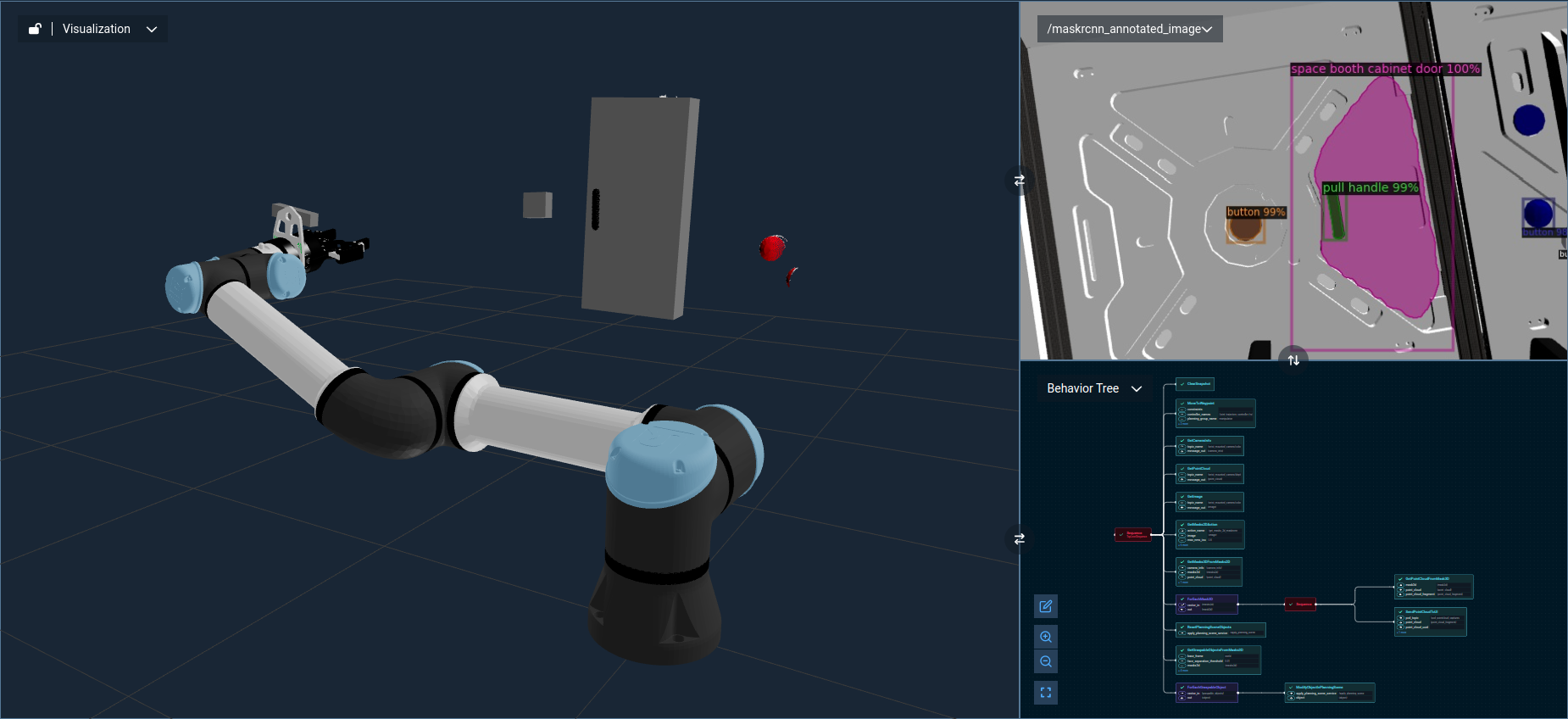
You can additionally extract graspable objects from the 3D masks and fit geometric shapes, using the following Behaviors.
GetGraspableObjectsFromMasks3Dto convert the 3D mask representations to graspable object representations, which include a cuboid bounding volume by default.ForEachGraspableObjectto loop through each of the graspable objects.ModifyObjectInPlanningSceneto visualize each graspable object (and its corresponding geometry) in the UI.
To run this example, execute the Object Segmentation 3D Objective.
Next Steps
Once you have detected 3D objects from 2D image segmentation, you can use the poses and shape of the detected objects for motion planning tasks. Some examples include pushing buttons, opening doors, performing inspection paths around objects of interest, or grasping objects based on their detected categories.
With this standardized ROS 2 action interface for image segmentation, you can switch to different model architectures and train models from your own datasets. This will enable you to create custom end-to-end applications using MoveIt Pro and machine learning based image segmentation models.